Have you noticed that:
- Data teams complain about overwhelming ad hoc requests.
- The same data teams are looking for ideas to create business value and wonder how to get organized to deliver it.
Faced with this, I find that self-service is (too) often brandished as a miraculous solution to “get out of ad hoc requests and finally work on advanced use cases.” As if we no longer wanted to hear about the business as long as it’s operational, day-to-day issues, and focus on the Magnum Opus, the famous use case that would be out of reach for business without data.
If you don't start by closely aligning with operations and the day-to-day business, you are on the wrong path [tweet this!]
In my opinion, this is a serious mistake. I spend my time telling anyone who will listen: if you don’t start by closely aligning with operations and the day-to-day business, as difficult as it may seem, you are on the wrong path.
This does not mean that self-service is not both useful and necessary for the business - but not automatically.
I can go even further: listening to business needs, especially through ad hoc requests, is essential for building a data organization that is a true partner.
But how do you resolve this apparent contradiction?
How do you accommodate the diversity and volume of requests while avoiding being overloaded or becoming a bottleneck, a limit to time to market?
How do you reduce the time spent on daily business requests while maintaining sufficient exposure to its challenges to fuel high-value solutions?
That’s the topic for today, and we’ll start by examining the nature of the requests that come to us.
Four Types of Ad Hoc Requests
Let’s take a closer look at requests and categorize them based on their recurrence and complexity:
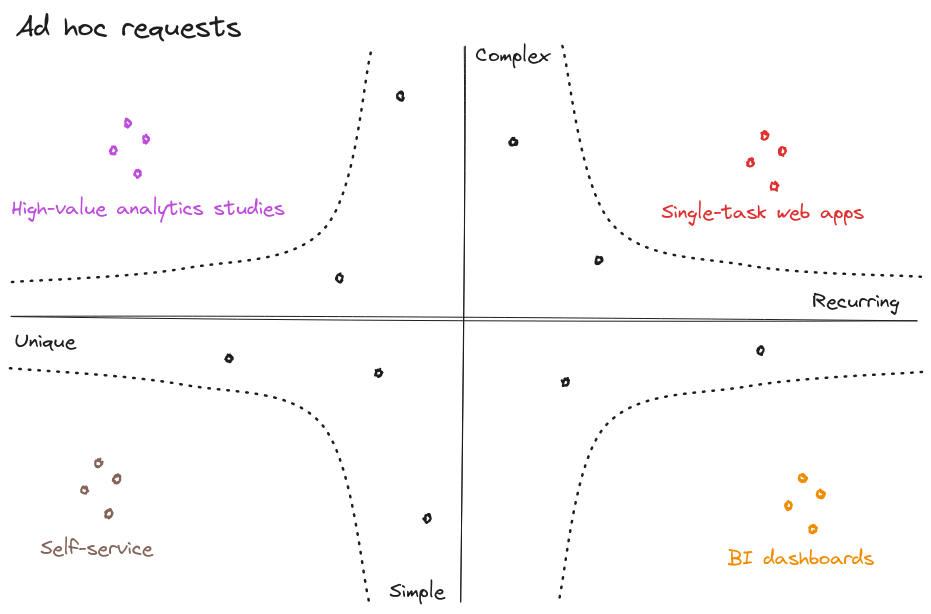
Four types of requests emerge:
- Repeated and simple queries should be integrated into BI tools.
Example: Is the latest collection of women’s accessories selling as well as last year at the same date?
- Unique and simple queries are good candidates for teaching users to be autonomous through self-service analytics.
Example: Extract the number of web transactions paid with gift cards since July 1, or the number of stores that held bow ties from brand Y for more than 8 weeks in a row.
- Repeated and complex queries are prototypes of dedicated data applications.
Example: Recommend the assortment or pricing level for a new store.
- Unique and complex queries provide opportunities for high-visibility and value-added studies.
Example: Discover the causes of a downward trend, determine if it is structural or cyclical, and the factors contributing to this trend.
If you receive complex requests, rejoice! They indicate trust from the business.
A side note: data teams, if you receive complex requests like the last two, rejoice! These kinds of questions indicate trust from the business in their data team, so it’s up to you to rise to the occasion!
Getting Your Head Above Water: Mutualize
Let’s say you take over a data team that is underwater: the business can’t take it anymore and complains about your team’s lack of responsiveness, your data scientists are tired of doing nothing but SQL and dream of joining a big tech company… but you know there are challenging problems to tackle.
How do you get out of this situation? There is no one-size-fits-all answer, and every situation will be different.
- Denying the problem won’t help.
- Asking for additional resources won’t be heard at this stage.
- Opening up access to all raw data, declare self-service open, and then focus on a standalone AI use case won’t work. A sensible mind should stop you before you go down that path.
The solution is iterative, through a gradual process that alternates between creating value and consolidating your data platform:
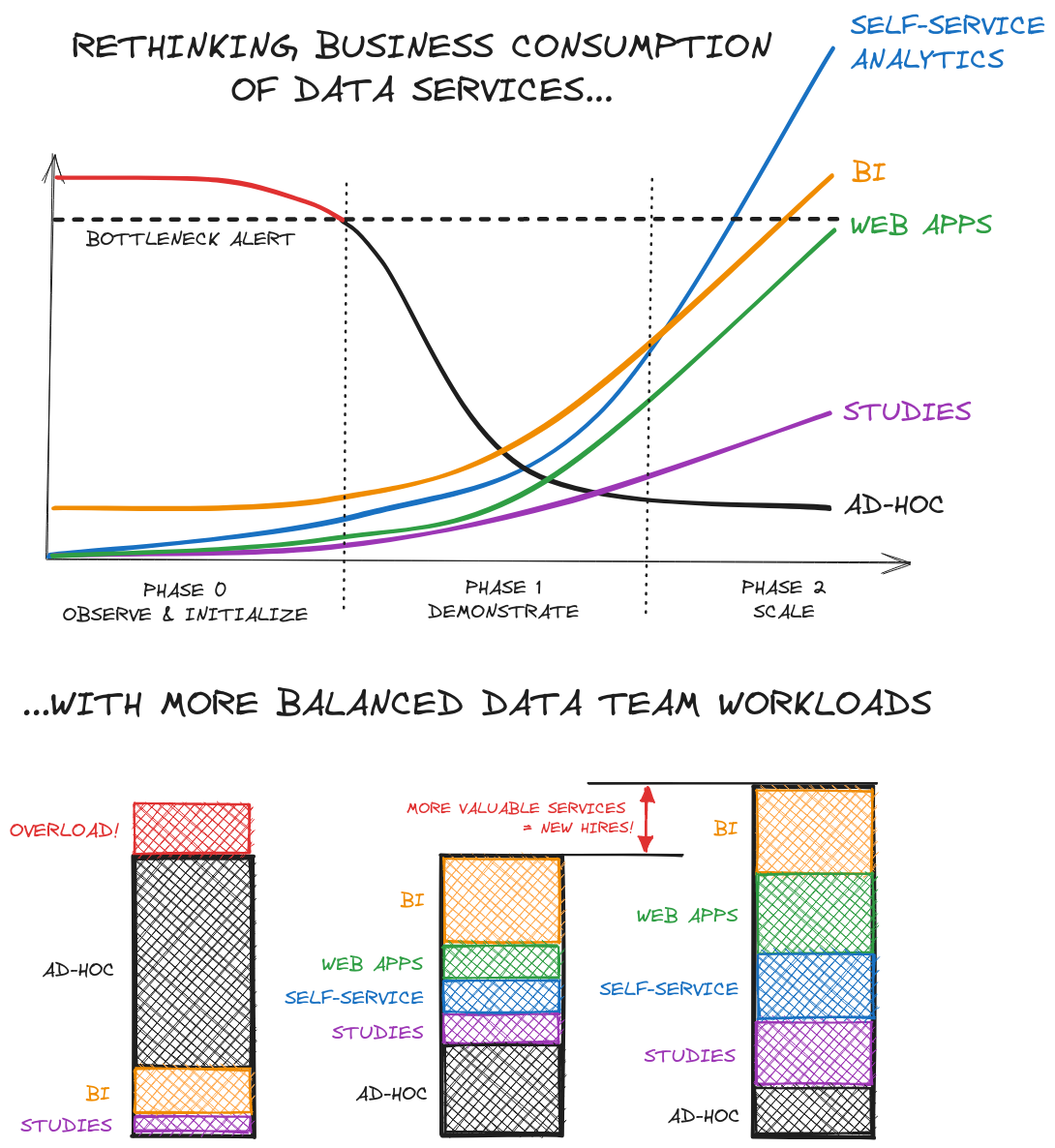
Phase 0: Observe, Initialize
In most cases, the most immediate raw data is already poured into a Data Lake or normalized in a Data Warehouse.
You will repeat two steps from this point:
- A data analytics step: by observing ad hoc requests, you can identify patterns that likely already translate into duplicated code for handling different requests.
- This is followed by a data engineering step that will define the aggregates to be built, new data to acquire, to create a first set of tables oriented toward usage: first to streamline and ensure the reliability of future ad hoc requests, and quickly to feed BI and self-service analytics.
From this step, the first elements of CI/CD, orchestration, and initial testing should be in place.
Phase 1: Demonstrate
Repeating these two steps will gradually lead to a richer data platform that can respond more quickly to a growing number of needs, freeing up bandwidth.
This bandwidth will allow you to:
- multiply the tables available for self-service: data resulting from properly tested pipelines, which the business can then reuse with minimized error risks
- develop BI dashboards that answer more and more simple questions
- set up, with infrastructure team support, initial use cases of dedicated web apps for certain complex questions
At the end of this phase, the initial elements of a complete data services offering are in place and bring value by accelerating or optimizing decisions.
During this stage, especially as you start using more compute and web services, you should start laying the foundation for monitoring and observability, both from a service maintenance and cost perspective: best practices, query optimization, reasoned but sufficient testing strategy. If web apps include machine learning, you will also need to establish the basis for model management and monitoring: monitoring indicators, retraining…
This added value will justify moving to a slightly larger team that will specialize in offering and maintaining these different services on a larger scale. And now, with this demonstration and vision, you are more likely to be heard.
Phase 2: Scale!
As the offering becomes broader, exposure becomes larger, and expectations become higher… but so does the impact!
During phases 1 and 2, the technical foundations will have been laid. Now it’s time to enter into an industrialization and scaling phase that will allow for a stronger orientation toward the business while ensuring service quality:
-
The Data Leader’s effort will focus more on supporting business strategy, particularly by working with more business units.
-
The effort, and therefore the number of analysts, should be able to grow the most with maturity and the number of needs: this is where the intersection of business and technology takes place, where it all begins!
(At this point, the goal is not necessarily to recruit only centralized analysts in the data team but to identify and/or recruit analysts in each business unit, moving toward a hub and spoke model with a central center of excellence and ambassadors.)
-
The effort of data engineers will increasingly focus on maintaining and monitoring a growing number of pipelines and products.
-
Data scientists can progress on two fronts:
- firstly, engage in a deeper, forward-looking work to identify innovative methods, enrich their model’s input data,
- secondly, increase their exposure to both business and data engineers to envision, propose, and design new solutions.
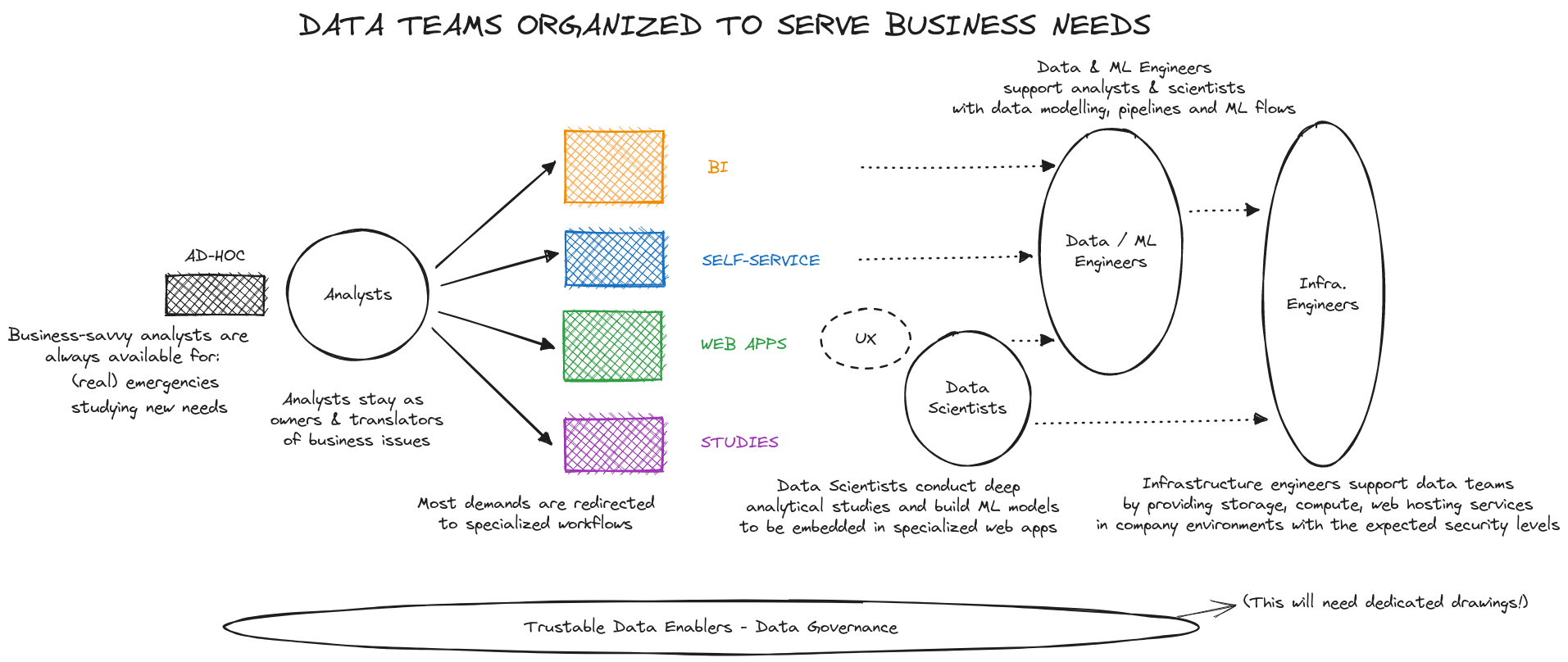
By systematizing and expanding the development of different components of your service offering, the time to handle ad hoc requests will decrease, without ever disappearing. More importantly, when carried out optimally, this organization ensures that analysts, who will always be the entry point to the system, have the availability to respond to business needs and questions!
Distributing Requests and Identifying High-Value Use Cases: A Team Effort
How do you go about distributing requests? For the majority of them, the decision can be relatively simple:
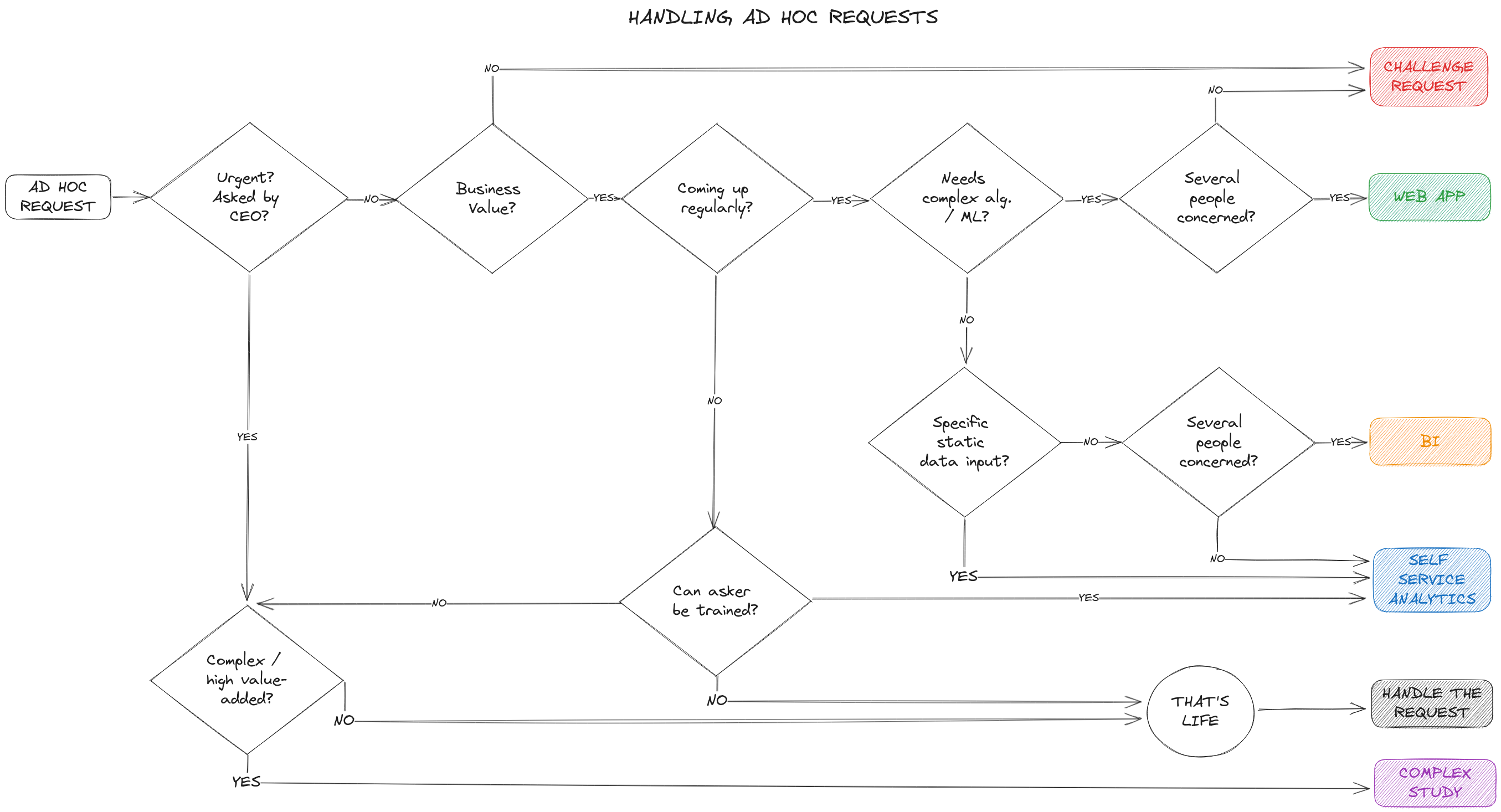
For more complex cases, trust the collective: by approaching requests together in team meetings, solutions emerge.
Among the many advantages of this collective approach:
- Sharing an overview of requests helps identify patterns and outline products to offer to the business.
- Sharing each other’s developments helps refine the architecture of the platform.
- Sharing difficulties related to data quality feeds the ongoing actions of data governance (a topic I touch on briefly but deserves entire articles).
As you can see, several arrows in the diagram above lead to self-service. They correspond to cases, and only cases that both result from a self-service request and are compatible with it. In these situations, both the business and data teams will agree that the business can freely build its analyses, supported by knowledge management and data governance to limit risks. At any time, business teams involved in self-service development can pass through the data team’s door.
That’s all for today!
Where is your organization at? Phase 0, phase 1, phase 2? Among the various steps and actions discussed in today’s article, which one seems the most challenging to implement?
Please note! I have omitted or barely touched on many issues that arise along this path, especially regarding data governance. But I remain convinced that governance and all the complexity it can bring to a large organization should come gradually, organically. For each new data-driven need, there is a governance effort to be made. Thinking about the data’s lifecycle, identifying who can take care of it at each stage, judging its quality… It’s easier to build consensus step by step, evolve from there, than to try to map everything out before being useful.
If I were to talk about governance or knowledge management, which topic would you like me to address first?
Your feedback helps me choose which topics to cover among the many that need attention, so feel free to contact me on LinkedIn or via email: gansanay AT gmail DOT com.